- [ Tech ]
- [ Architecture composable ]
- [ MACH ]
- [ CMS headless ]
Architecture composable : une alternative moderne aux monolithes
Gilles Guirand
Publié le 9 février 2026
Le choix d’architecture, notamment l’architecture composable, a un impact sur la dimension organisationnelle, technique et financière d’un projet numérique. De nouvelles alternatives émergent sur le marché, mais impliquent parfois de revoir la conception du projet, le savoir-faire et les compétences disponibles dans les équipes, ainsi que l’organisation de l’équipe projet.
Quelles sont les solutions disponibles et comment faire son choix pour assurer la rentabilité, la scalabilité et la pérennité de son projet ?
La fin des monolithes et l’émergence de l’architecture composable ?
Depuis les années 2000, les entreprises et e-commerçants plébiscitent l’utilisation de CMS et solution eCommerce monolithiques, c’est-à-dire “tout en un” : capables à la fois de fournir des interfaces d’administration très fonctionnelles, mais aussi un front-end, de la recherche, de l’authentification, des formulaires, des newsletters… au final tout ce dont on a besoin pour démarrer un nouveau projet Web. Si ces solutions ont permis à un grand nombre d’acteurs d’accélérer leur digitalisation, elles ont ensuite souvent atteint un plafond de verre et une incapacité à s’adapter aux nouveaux usages mobile (natif ou PWA), à profiter des promesses du Cloud (scalabilité), et sont progressivement devenues un héritage très lourd à maintenir, peu désirable pour les ingénieurs, parfois vulnérable et fonctionnellement dépassées par les outils spécialisés sur une seule fonction : recherche, newsletter, authentification, etc.
L’architecture MACH et composable comme alternatives ?
En effet miroir, à l’extrême opposé des monolithes, les micro-services, et plus particulièrement les architectures MACH (Microservices, API-First, Cloud-Native, Headless) ont émergé comme alternative dogmatique et incontournable aux monolithes. Et quelques acteurs Cloud/SaaS et start-up de haut niveau ne pouvant pas se passer d’un tel niveau de scalabilité et sachant gérer les complexités et nouvelles expertises qui en découlent, ont réussi à intégrer ces architectures avec succès. Cependant, pour bien d’autres acteurs, le gap d’ingénierie à franchir est insurmontable et les inconvénients des architectures MACH sont supérieurs aux bénéfices espérés. Alors comment concilier le meilleur des deux mondes ?
« Headless Experience Conf' » dédié au Front-end Vue/React
Tour d'horizon des technologies front-end, table ronde avec des experts, retours d'expérience terrain et tech talk sur les design systems, moteurs de rendu SSR/SSG et gestion des images
L’architectures composable, le meilleur des deux mondes ?
Headless – Découplages front-end & back-end
Le simple découplage front-end et back-end a permis et permet encore de débloquer de nombreuses situations de roadmaps digitales paralysées par les monolithes legacy, à savoir
- pouvoir moderniser le front-end et les usages en mobilité (PWA, offline, performance) sans dépendance avec le back-end ;
- pouvoir utiliser les FrameWorks, librairies et outils de productivité modernes attendus et désirés par le plus grand nombre de développeurs, actuellement Vue, React ou Svelte ;
- pour découpler les roadmaps front et back sans blocage respectif ;
- pouvoir conserver tout ou partie du back-end monolithique, en le remplaçant progressivement, sans besoin d’un effet tunnel sur plusieurs années.
Cependant ce travail n’est pas sans conséquence sur les adaptations et investissements nécessaires autour des CMS monolithiques, qui exposent souvent de la logique métier au niveau du front-end, devant être déportée vers les API pour éviter de recréer une dépendance front et back, et finalement dénaturer l’un des intérêts du headless : le découplage de responsabilité.
Design atomique et logique de composants
La promesse d’une architecture composable, comme son nom l’indique, est de pouvoir “composer” un produit digital à l’aide d’éléments étanches entre eux, permettant des évolutions et des remplacements de chaque élément sans incidence sur les autres éléments du système. Découpler le back du front ne suffit pas à garantir cette promesse, encore faut-il ne pas recréer un monolithe à l’échelle du frontend, où toute évolution visuelle ou fonctionnelle nécessiterait de repenser, retester, dupliquer et déformer l’existant.
Le design atomique, documenté dans un storybook, permet ainsi de construire un langage visuel et fonctionnel constitué d’atomes (une icône), de molécules constituées d’atomes (bouton), d’organismes constitués de molécules (footer), etc. Ce langage permet de composer tous les types de pages sans doublon, exotisme ou macro dépendance.
Paradigme de rendu HTML
Dans un monde headless, ou le back-end expose exclusivement des API et des données en JSON, se pose la question de la stratégie de rendu HTML, à savoir :
- Quelle page ou portion de page doit être rendue côté navigateur, par exemple les contenus personnalisés par utilisateur, non prédictibles (autocompletion de recherche) et donc non cacheables ?
- Quelle page ou portion de page doit être rendue côté serveur, parce que devant être cachée pour des considérations de performance et exposée aux robots d’indexation ?
Pour les pages générées côté serveur se pose également la question de ce qui peut être généré de façon statique (Server Side Generating, concept clé d’une JamStack). Ce paradigme est de loin le plus performant parce qu’il n’expose que des contenus statiques cachés sur un CDN, mais aussi le plus exigeant et complexe à mettre en œuvre dans un contexte de gros volume de contenu, de personnalisation. C’est pourquoi le Server Side Generating s’est popularisé comme le meilleur compromis entre performance et simplicité, en générant le HTML côté serveur lorsqu’un internaute demande une page expirée sur le CDN.
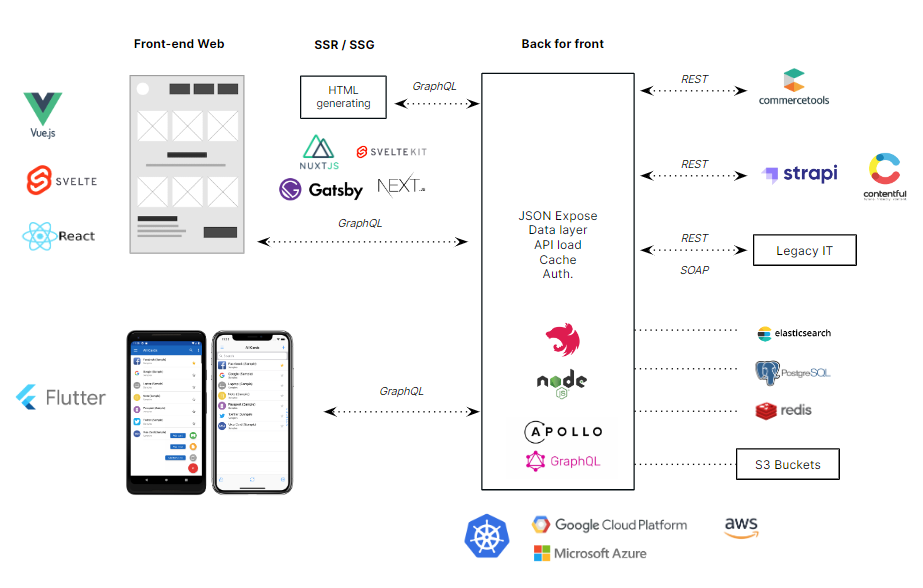
Pourquoi un Backend For Frontend ?
Un découplage front-end et back-end recrée indirectement une dépendance lorsque le front-end requiert directement le ou les API back-end, par exemple l’API du CMS, l’API de recherche et les autres API du système d’information. Le front-end redevient alors monolithique en jouant le rôle d’orchestration et la liaison entre les API, avec les problèmes de logique métiers, d’authentification et de performance qui en découlent.
C’est pourquoi les architectures composables nécessitent la présence d’un nouveau back-end entre le front-end et les autres API du système, permettant ainsi de :
- exposer une unique API back-end pour les appels front-end, dédiée et adaptée à l’expérience utilisateur front-end, de préférence en GraphQL pour limiter les allers-retours entre le front et back ;
- ne jamais exposer en direct les API métiers ou CMS pour des raisons de sécurité, de performance et de découplage (pouvoir brancher, débrancher de nouvelles API selon la roadmap) ;
- charger les données des systèmes back-end métiers (API REST, SOAP, fichiers..) et des solutions d’éditeurs (headless CMS) pour les lier entre elles, les adapter, les transformer vers l’API servie au front-end ;
- stocker les données nécessaires de façon persistante (données inexistantes sur les back-end métiers) ou temporaire (cache volatile, index de recherche), au cas par cas selon le besoin fonctionnel ;
- unifier l’authentification JWT aux divers systèmes, pour proposer un uniquement jeton JWT d’échange avec le front-end ;
- utiliser des systèmes de cache en entrée (réponses API métiers) et en sortie (cache HTTP) pour protéger les API métiers et le back for front lui-même de trop d’appels.
Quand choisir du REST et quand choisir du GraphQL ?
GraphQL s’est largement démocratisé pour sa capacité et laisser le front-end maître de faire varier les requêtes et sélectionner les champs, tri et filtres de données dont il a besoin pour un affichage sans dépendance avec le back-end. Le front-end peut ainsi obtenir, avec un minimum d’appels et un maximum de flexibilité, les données JSON pour peupler les composants.
GraphQL reste le meilleur choix pour ce dialogue entre interface visuelle et fournisseur de données de type back for front. Cependant, pour l’exposition d’API plus atomique et générique, non directement couplée au front-end, REST reste un meilleur choix, moins permissif et plus facile à stabiliser dans un contexte de serveur à serveur, ou pour exposer une API métier non influencée par une interface utilisateur.
Exemple de schéma d'artchitecture composable :
L’architecture composable, solution de replatforming ?
Les monolithes ont cette faculté de rendre difficile un replatforming vers une architecture composable. Ne sachant pas toujours par quoi commencer, et ayant parfois la peur de l’effet “château de cartes”, les décideurs peuvent investir indéfiniment sur des montées de version jusqu’à épuisement ou disparition de la solution et des compétences associées.
Les scénarios généralement entrepris comme premières étapes vers une architecture composables sont :
- Le découplage complet front-end et back-end (100% API), parfois difficile lorsque le monolithe ne propose pas une couverture fonctionnelle en API. Cependant, l’investissement pour développer les API manquantes est souvent profitable au long terme, dès lors qu’on peut tirer profit d’un front-end indépendant.
- Le découplage progressif front-end et back-end en utilisant des artifices d’inclusion du nouveau front-end progressivement par widget javascript, par ESI (edge-side-include), par des astuces d’expérience utilisateur (pleine page et bouton retour, panneau latéral).
- Le découplage progressif back-end en parallèle du front-end, en remplaçant des fonctions du monolithe par des outils externes progressivement (recherche, newsletter, formulaires, etc..).
« Headless Experience Conf' » dédiée aux CMS headless
CMS headless, ou le pouvoir de la conception par Imbrication
Les architectures composables et les challenges associés
Les architectures composables permettent de débloquer des situations paralysées et proposent bien des atouts. Mais elles amènent également leur lot de nouvelles complexités, nouveaux savoir-faire, nouveaux défis :
- Cela nécessite d’apprivoiser de nouvelles compétences et un nouveau vocabulaire : les développeurs Full Stack JavaScript, ou encore TypeScript, graphQL, les paradigmes de HTML rendering, les JamStack, les déploiements continus sur le Cloud, Kubernetes ou encore l’infrastructure as Code (Terraform)…
- Il faut élever le niveau d’expertise : sur le DevOps, sur la performance, sur l’architecture de code, sur les API, sur le Cloud…
- Cela peut engendrer un choc culturel et générationnel : la génération PHP qui se sent déconnectée d’un nouveau monde qui leur paraît inaccessible, et les sorties d’écoles qui maîtrisent ce nouveau monde comme étant le seul possible et désirable.
Mythes et légendes autour de l’architecture composable
Le choc générationnel entraîne son lot de craintes, d’appréhensions, de résistances et au final quelques mythes et légendes, qui font et feront encore débat sur les prochaines années, émergent. Voici un extrait de questions et réponses, toutes valables ou non.
“Il est plus difficile de recruter un développeur full stack JS que PHP.”
VRAI : Les architectures composables nécessitent un niveau d’ingénierie qui mettent les entreprises et e-Commerçants sur le même terrain de jeu que les pure players digitaux et les Start-up. La compétition au recrutement est difficile.
FAUX : En volume, la grande majorité des sorties d’école sont familiarisées avec cette culture d’ingénierie, devenue le nouveau standard. 90% des CV reçus par les ESN comme Kaliop et ses concurrents sont des développeurs front-end, back-end ou full stack de culture JavaScript, Cloud et Headless.
“Les technologies JavaScript sont des effets de modes.”
VRAI : De nouveaux frameworks et librairies apparaissent chaque semaine, et très peu survivent au profit des écosystèmes maintenant matures comme Vue/Nuxt, React/Next, Gatsby, Apollo, Nest, etc. Il est difficile de suivre les tendances et de miser sur le bon cheval.
FAUX : JavaScript et les principaux frameworks qui le portent ont atteint un niveau d’adaptation et de diffusion dans le monde du Web (front et back) et du Cloud, qui constitue un point de non retour, en attente d’une révolution majeure qui rendrait obsolète le concept de navigateur Web. Par ailleurs, le caractère volatile du Web mitige la volatilité des frameworks et leurs versions.
“Le headless est un appauvrissement fonctionnel.”
VRAI : Par nature, une solution headless se focalise sur une unique fonction et s’éloigne volontairement d’une ambition de “tout en un”.
FAUX : En associant les meilleures solutions headless spécifiques à chaque fonction (CMS, identité, formulaires, newsletter, paiement, CRM, etc.), on obtient un ensemble difficilement concurrençable par un seul éditeur de solution monolithique.
“La complexité des architectures headless rend difficile la maintenance.”
VRAI : Les compétences d’intégrateur de solution d’éditeur ou de webmaster deviennent peu exploitables dans ces écosystèmes qui font appel à des compétences d’ingénieurs qui jusqu’ici s’intéressaient moins au Web qu’à d’autres disciplines.
FAUX : Les compétences sont nouvelles pour le Web mais pas dans le milieu de l’IT et du développement informatique. Ce qui paraît ainsi “complexe” ou inaccessible pour un intégrateur Web est un lieu commun pour un ingénieur.
Contenus similaires
[ Article ]
Comment GraphQL Codegen améliore l’expérience de développement frontend avec un Backend-for-frontend

Baptiste Leulliette
[ Article ]
L’observabilité 360° : du monitoring technique au pilotage de la valeur digitale

Emmanuel Valluche
[ Article ]
Contentful : le CMS Headless de référence pour bâtir une expérience e-commerce omnicanale composable

Pierre Cavalet



