Créer un système de recommandation réversible avec ElasticSearch
24 juillet 2019
Les systèmes de recommandation sont partout. On peut trouver une multitude de techniques complexes pour faire de la recommandation, mais parfois, des règles simples peuvent suffire à avoir un système pertinent.
Un peu de contexte
Mon équipe travaille sur des fonctionnalités de contenu. Notre système de recommandation a une contrainte forte : chaque résultat présenté à un utilisateur doit pouvoir être expliqué. Par exemple, si un utilisateur se rend sur la page d’accueil et qu’il voit un article appelé Mon avis sur la dernière saison de Game of Thrones, nous devons être capable d’expliquer pourquoi.
Quand l’algorithme de recommandation se contente de trier les articles par date de publication, il est assez simple d’expliquer les résultats. Quand les résultats sont basés sur les préférences utilisateur, ce qu’il a déjà lu et d’autres critères, l’explication exacte est plus difficile à obtenir.
Comment ça fonctionne
L’algorithme est assez simple à comprendre. Il faut d’abord définir une liste de critères qu’un contenu peut remplir, puis les classer par ordre de priorité. Chaque critère doit être une variable booléenne (vrai/faux). Disons que notre système recommande des articles.
Ordre de priorité :
- L’utilisateur n’a pas lu l’article
- Au moins un des tags de l’article correspond à un des tags de l’utilisateur
- L’article est marqué comme important
Note : cette liste est juste un exemple. La liste peut être plus bien plus grande, tant qu’elle est ordonnée. L’ordre de priorité est complètement arbitraire.
Maintenant, il faut assigner un score à chaque critère. Nous allons assigner des puissances de 2, en commençant l’assignation par le bas de la liste.
- L’utilisateur n’a pas lu l’article : 2³ = 8
- Au moins un des tags de l’article correspond à un des tags de l’utilisateur : 2² = 4
- L’article est marqué comme important : 2¹ = 2
Imaginons un utilisateur appelé John.
John n’a pas lu Mon avis sur la dernière saison de Game of Thrones, mais aucun des tags de l’article ne correspond aux tags de John. Enfin, l’article est marqué comme important par l’équipe de contenu.
L’algorithme fait la somme des scores des critères que le contenu rempli pour obtenir son score final : 8 + 2 = 10.
En répétant ce processus pour chaque article, il est possible de classer les articles en fonction de leur score. Les articles les mieux notés seront affichés sur la page d’accueil de John.
L’utilisation des puissances de 2 est expliquée plus loin dans cet article.
Implémentation avec ElasticSearch
Voici les documents utilisés pour l’exemple. Chaque document représente un article et tous les documents sont indexés dans un seul index.
ElasticSearch fournit un outil appelé function score function score query. Il permet de modifier le score d’un document dans une requête, en se basant sur des critères particuliers.
Par exemple, je peux faire une première requête qui récupère tous les articles, puis utiliser des requêtes de filtre sur mes résultats pour changer le score des articles que John n’a pas lus. Imaginons que John a lu l’article avec l’ID articleId2.
Note : si la requête filtre les documents au lieu de tous les récupérer (match_all), on peut utiliser constant_score pour ne pas altérer le score final du document avec la requête de tri.
On peut ensuite ajouter les fonctions pour les tags et le flag important:
Voici le résultat de la requête :
Comme on peut le voir, ElasticSearch retourne le score de chaque document de sa réponse, ce qui est parfait pour la suite : récupérer les informations à partir du score. C’est le moment de répondre à la question suivante :
« Pourquoi utilise-t-on des puissances de 2 ? »
L’utilisation des puissances de 2 n’a pas été faite par hasard. Nous avons choisi d’utiliser des puissances de 2 car elles sont idéales pour stocker des informations booléennes. 0 correspond à faux, 1 correspond à vrai. Stocker des informations dans des puissances de 2 s’appelle un bit field (ou un bit flag).
De plus, cette technique produit une relation 1-1 entre l’entrée (les informations booléennes) et la sortie (la valeur du bit field), ce qui veut dire qu’on peut récréer les informations booléennes à partir du bit field. En d’autres termes, on peut retrouver les informations de l’article à partir du score pour pouvoir expliquer le résultat.
On récupère les informations de la manière suivante :
Note : on saute le premier bit car le score par défaut d’ElasticSearch est 1. La première puissance de deux est donc déjà utilisée (2⁰ = 1). Dans cet exemple, le rouge est sauté :
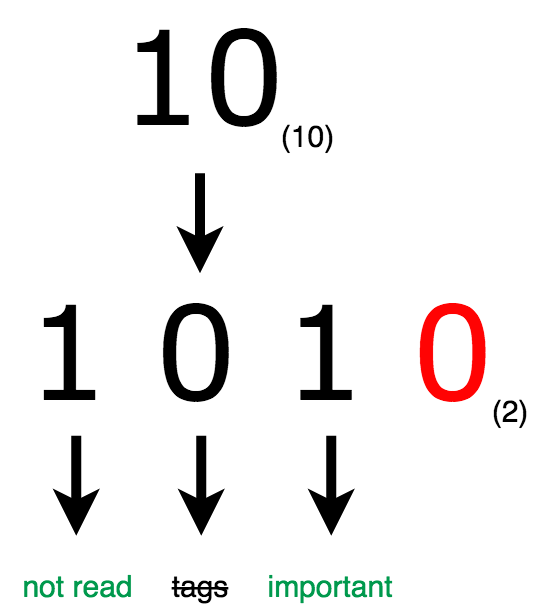
Donc … si je converti mon score (10) en sa valeur binaire (1010), alors je peux récupérer les informations qui étaient « vraies » ?
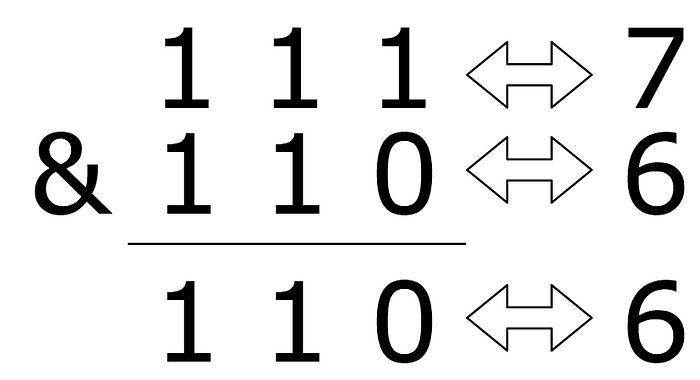
Oui, mais il y a une meilleure façon de faire. On peut utiliser un opérateur bit-à-bit pour extraire les informations. Plus particulièrement et ET bit-à-bit. Il permet d’appliquer une opération ET entre chaque bit de deux nombres donnés. Par exemple 7 & 6 = 6:
Maintenant, si on utilise uniquement un bit spécifique avec un ET bit-à-bit, on peut déterminer si le bit field contient cette information, car tous les autres bits vont donner 0.
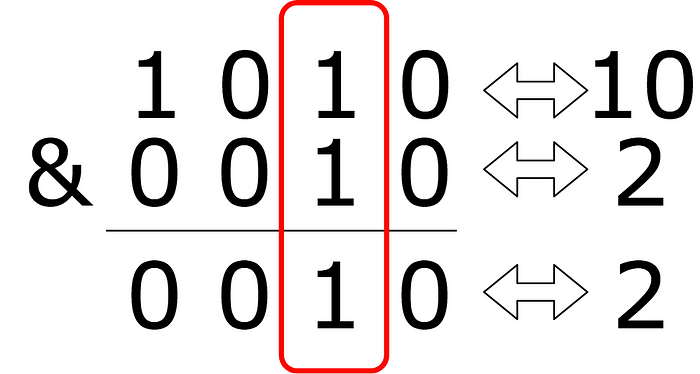
Ici, on extrait uniquement une information. 10 & 2 ≠ 0, donc l’article est marqué important.
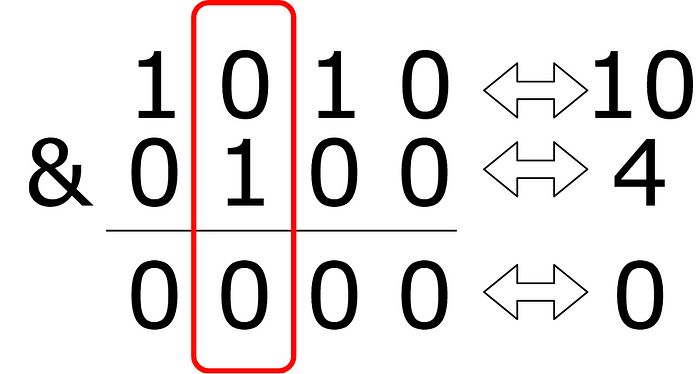
10 & 4 = 0, l’utilisateur n’a donc aucun tag qui correspond aux tags de l’article.
En utilisant cette technique, on peut facilement écrire un script qui permet de décoder un score donné, ce qui est exactement ce qu’on souhaitait.
Voici un exemple d’un script pour décoder un score en javascript. Il est assez facilement reproductible dans un autre langage :
Récap
- En utilisant des puissances de 2 pour le score des documents, on peut représenter une relation 1-1 entre les informations booléennes et le score.
- On peut utiliser ce score pour classer les documents pour afficher des articles qui correspondent à l’utilisateur.
- On peut déterminer à partir du score les informations booléennes pour expliquer pourquoi un article s’affiche sur la page d’un utilisateur.
- Pour implémenter cette technique, on utilise les function score queries d’ElasticSearch.
- John peut lire des articles qui correspondent à ce qu’il aime.

Expert technique
Commentaires
