- [ Tech ]
- [ Frontend ]
Que se passe-t-il dans la tête d’un front ?

Jordan Dey
Publié le 10 janvier 2020
« Les frontends… Quelle drôle d’espèce ! » Souvent vus comme des artistes, leur travail est plutôt mystérieux pour bon nombre de personnes. On les appelle et ils utilisent leur magie pour rendre beaux nos formulaires. Nous allons tenter d’entrer dans leur monde pour mieux les connaître. Faciliter les échanges avec eux a plusieurs vertus : cela fera gagner du temps si l’on passe après eux, et cela améliorera le code qu’on leur laisse si l’on passe avant. Pour cela nous verrons quelles sont les conventions de travail mises en place par les frontends, afin de les comprendre et de pouvoir les appliquer.
Nous aborderons les sujets suivants : construction du CSS, la structure HTML et pour terminer celle des données. Dans chacun de ces points nous nous intéresserons aux bonnes pratiques de base à connaître. Il s’agit de choses très simples à mettre en place et qui n’allongeront pas le temps de développement. Promis !
Structure CSS
1) Notion de composant / Sous-composant / Élément
« Comment nommer ses classes ? » Le nommage de ses classes est très important, puisqu’il doit refléter l’architecture des composants. Pour un front, tout est composant. Lorsqu’il visite un site web, il ne peut pas s’empêcher de découper les parties qui, visuellement, se ressemblent. Ce découpage lui permet d’identifier les composants qu’il va pouvoir réutiliser (ou rendre réutilisables).
Prenons l’exemple suivant :
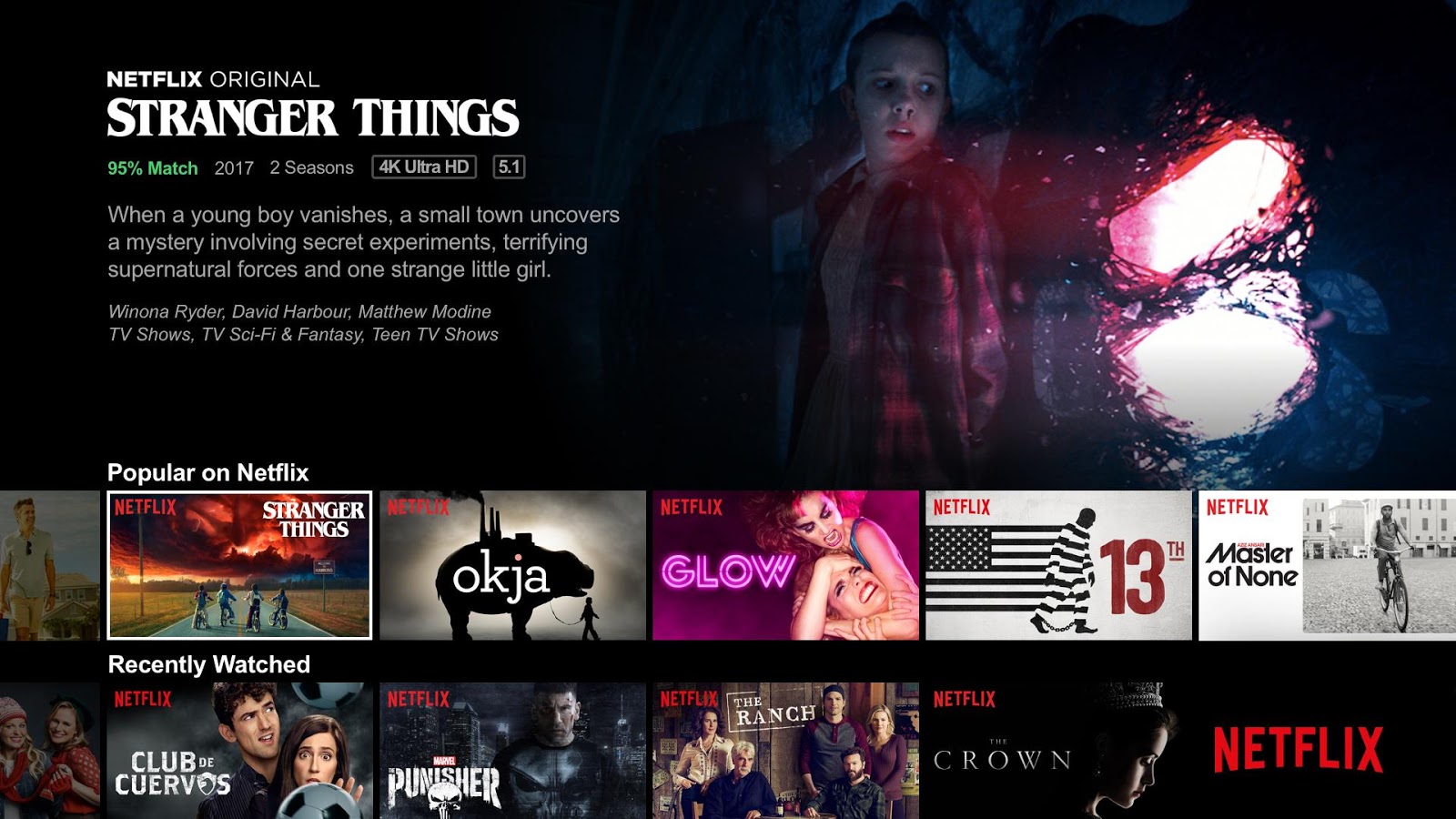
Premièrement, on peut voir qu’il s’agit d’une ancienne interface de Netflix. Il n’y avait encore que deux saisons de Stranger Things.
Sur cette page nous identifions deux composants. Le premier serait le teaser en pleine largeur présent en haut de page. Le second, présent deux fois, est une liste de contenus avec un titre.
Ils sont mis en évidence ci-dessous :
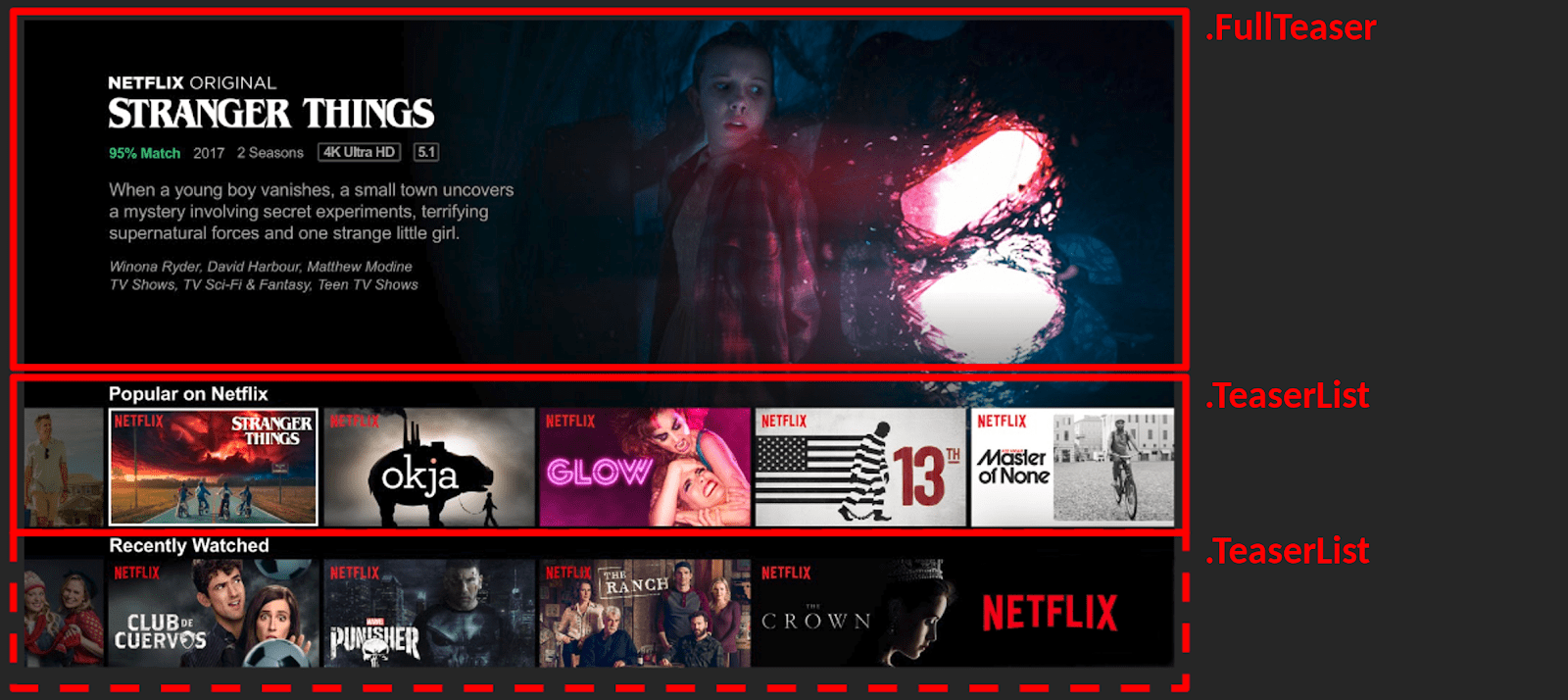
Comment les auriez vous nommés ? Ici, .FullTeaser est présent en haut de page, on serait tenté de le nommer .TopTeaser . Pourtant, il vaut mieux éviter d’ajouter la position du composant dans son mon, car sur une autre page, il pourrait être utilisé à un autre endroit. Il en va de même avec les couleurs. J’éviterais de nommer un composant .MonComposantRouge , car si je dois le réutiliser à un autre moment mais avec une couleur différente, je vais me retrouver avec une classe qui ressemblerait à .MonComposantRouge–bleu . La règle générale est de ne pas donner d’information susceptible de varier dans le nommage de la classe. N’hésitez pas à demander l’utilisation que le client compte faire d’un composant pour vous aider. Cela permettra d’avoir en tête l’ensemble du site, de partager la vision qu’a le client afin de nommer et donc de réutiliser au mieux les composants.
Le découpage par composant offre l’avantage de pouvoir segmenter son code de manière cohérente. Pour chaque composant identifié, j’aurais un fichier style associé. Dans notre exemple, je trouverais le style associé à .FullTeaser dans _FullTeaser.scss (si j’utilise SASS).
Il peut être utile de remarquer les éléments qui se répètent à l’intérieur même d’un composant. On parlera alors de sous-composants.
Il est important de vous mettre d’accord avec l’équipe front sur une convention de nommage pour vos classes. Ici, j’utilise un système de nommage interne à Kaliop, inspiré de la convention BEM, pour Block Element Modifier, qui est la plus commune pour les frontends. Vous l’avez peut-être remarqué, pour nommer un composant, j’utilise le PascalCase. Cela me permet d’indiquer qu’il s’agit d’un composant et non d’une classe utilitaire qui, elle, serait en CamelCase. Tout comme les utilitaires, les sous-composants ou éléments s’écrivent aussi en CamelCase.
Exemple :
.MonComposant // un composant
.MonComposant-monElement // un élément contenu dans .MonComposant
.text-red // un utilitaire qui passe mon texte en rouge
Dans notre exemple on pourrait proposer :
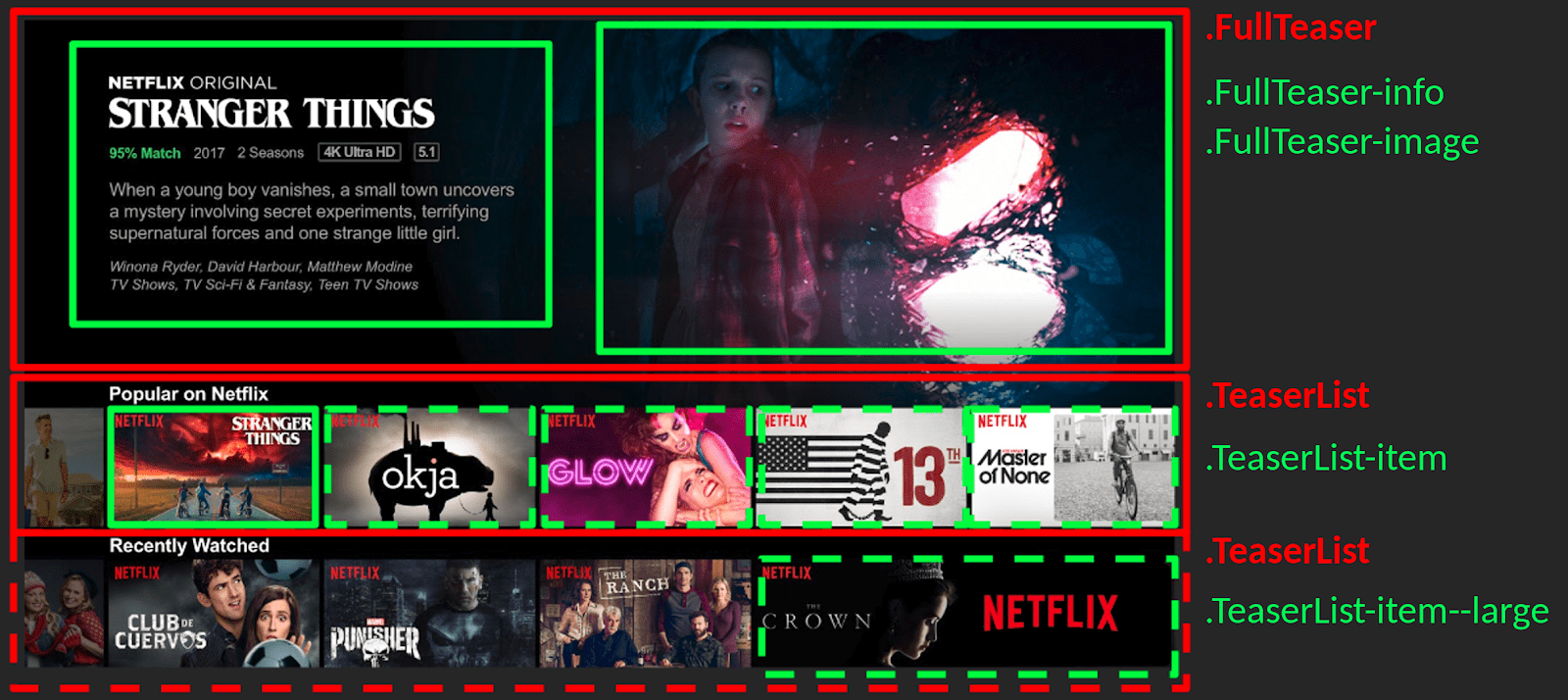
En cas de composant imbriqué, il ne faut pas hésiter à créer des composants plutôt que des sous-composants. On voit dans notre exemple que le block .FullTeaser-info contient beaucoup d’informations. Si l’on veut styliser le titre, on se retrouve avec .FullTeaser-info-title . Cependant, pour des raisons de maintenabilité et de clarté, il vaut mieux éviter de descendre au-delà de trois niveaux d’imbrication. Il faut chercher à toujours avoir un niveau d’abstraction le plus élevé possible. Ce bloc pourrait donc faire l’objet d’un composant distinct. Il serait alors réutilisable dans un autre contexte de manière indépendante. Mon sélecteur .FullTeaser-info-title deviendrait donc .MovieInformation-title . Bien sûr, le découpage change selon les frameworks ou votre équipe de développeurs.
2) Notion de variantes
Une variante est un élément qui a un affichage différent dans un contexte particulier. Une variante peut être créée pour changer une taille, une couleur, une position ou autre. Pour cela, nous l’indiquons en CSS par un double tiret ( — ). Notre .TeaserList-item devient donc .TeaserList-item–large .
3) Quelques #idées et beaucoup de .classe !
Le développeur frontend évitera au maximum d’utiliser un ID. Celui-ci étant supposé être unique, il fait un bien mauvais candidat pour un composant réutilisable. Mais ce n’est pas tout ! Un style sur un ID est très difficile à surcharger à cause du poids CSS.
Le poids css est ce qui permet de comprendre quelle règle est appliquée, parce qu’elle est considérée comme la plus importante. Pour cela un poids est attribué à chaque sélecteur possible. Je vous les présente ci-dessous :
| Nom | Forme | Poids |
|---|---|---|
| Balise | div | 1 |
| Classe | .maClasse | 10 |
| Identifiant | #MonIdentifiant | 100 |
| Style | <div style= »… »> | 1000 |
| Important | !important | 10000 |
- div.myClass { … }
- div#MyId p.myClass { … }
- .myClass, .otherClass { … } // attention, il y a une virgule.
- <span style=‘…’>
- div img { … !important }
- <a style=‘… !important’>
Structure Html
1) Pas de balises inutiles
Lorsque l’on prépare son code HTML, il faut être vigilant sur le fait de minimiser le nombre de balises. Si l’on évite les balises inutiles, c’est pour deux grandes raisons. Premièrement, pour un souci de lisibilité du code. Pour un humain, une balise n’apporte que peu d’informations, alors qu’une classe bien nommée permet d’avoir une idée claire du code que l’on est en train de lire.
Deuxièmement, afin d’avoir de meilleures performances. Lorsque l’on se réfère au sujet, lighthouse, l’outil de Google pour l’analyse de performances donne les recommandations suivantes :
- Avoir moins de 1500 nœuds au total.
- Avoir une profondeur maximum de 32 nœuds.
- Ne pas avoir de parent avec plus de 60 nœuds enfant.
Il explique par la suite que l’on gagne en performances de transferts. Un code source avec moins de balises étant plus rapide à télécharger pour le client. Les performances seraient également meilleures en temps d’exécution puisque la création du DOM virtuel serait plus rapide. Enfin, les performances de mémoire seraient elles aussi meilleures puisque lors d’analyses du virtual DOM, celui-ci serait plus léger. Si vous désirez étudier le sujet plus en profondeur vois-ci la documentation en question : https://developers.google.com/web/tools/lighthouse/audits/dom-size
Dans la pratique, cela veut dire ne pas utiliser les balises pour le style, tel que <u> ou <b>. Le style doit être fait à partir des fichiers prévus à cet effet. Il faut se dire qu’une balise n’est pas compréhensible par un être humain alors qu’un nom de classe oui. .text-underline est plus clair qu’une balise <u> . Attention, on parle ici seulement du style et non de la sémantique qu’apporte une balise. Dans la pratique, un <h1> est utile pour la structure de son document et son SEO, il faut donc le conserver.
2) Un composant par fichier
Dans le cas idéal, un composant devrait pouvoir vivre de manière autonome. Peu importe son contexte, il doit être capable de s’afficher correctement.
Avec un fichier par composant, il est plus facile de retrouver le code qui lui est lié si l’on harmonise le nom de tous les fichiers liés à celui-ci.
Par exemple :
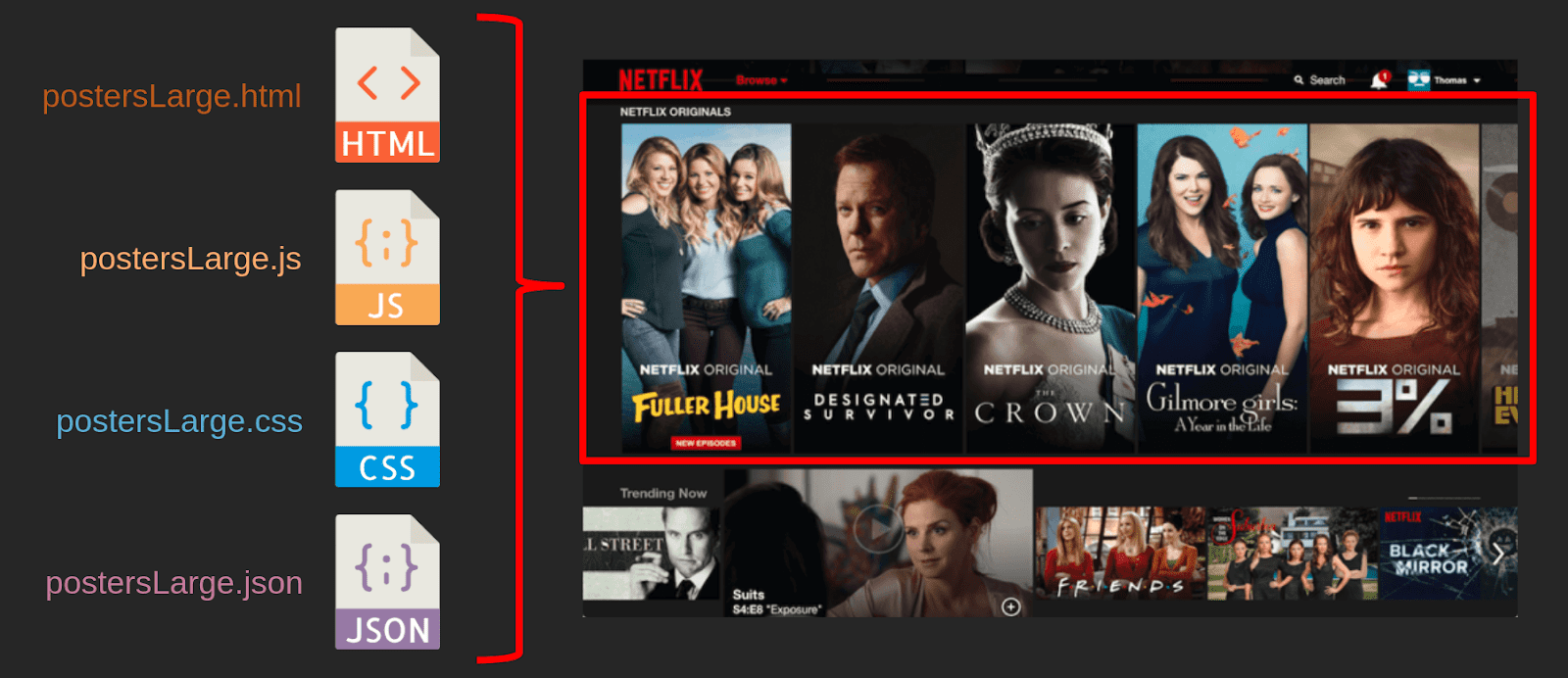
Dans le cas où on l’on devrait modifier ou corriger un composant, une inspection avec les outils de développement nous permettrait de retrouver immédiatement le fichier qui nous intéresse. Qu’il s’agisse de structures, d’actions, de style ou de sources de données, tout ce qui est lié à ce composant porte son nom.
Cette méthodologie pourrait avoir l’inconvénient de devoir charger une multitude de fichiers pour afficher une page construite à partir de plusieurs composants. Cela pourrait créer notamment des soucis de performance. Heureusement, nous avons des outils de bundle de code qui nous permettent d’obtenir un seul fichier de sortie. Celui-ci sera plus lourd certes, mais chargé une seule fois par le navigateur puis mis en cache. De plus, sachez que ces outils permettent également de mettre en place du code splitting. Dans ce cas, il est possible de découper son fichier final en plusieurs fichiers chargés uniquement si l’on en a besoin.
Si le sujet vous intéresse, je vous invite à consulter cette article : Réduire son bundle JavaScript avec du code splitting.
Structure de données
Dans cette dernière partie, nous aborderons le sujet des sources de données et de leur format. Un composant générique devrait pouvoir être dépendant de toute source de données. Cela veut dire qu’il ne doit pas connaître la structure de donnée. Il définit sa propre structure sur les informations qu’il utilise. Pour cela nous pouvons mettre en place un DAO (Data Access Object). Il s’agit d’un objet qui offre une interface abstraite à une source de donnée.
Ci-dessous, le composant movie.vue s’attend à recevoir un objet qui a la propriété title. Mais une base Contentful lui envoie une structure différente. Le contrôleur en charge du rendu de la page va donc devoir utiliser un DOA pour formater l’objet movie dans une structure exploitable par le front. Cette structure doit impérativement être discutée et connue par tous les développeurs sur le projet.
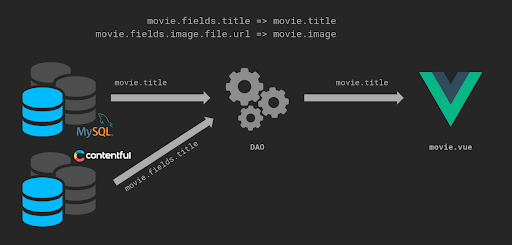
Le DAO n’est pas à la charge de l’une ou l’autre partie. Frontends et backends peuvent tous les deux le maintenir et le faire évoluer. Il revient à chaque équipe de définir comment elle s’organise pour cela. Par exemple, la règle pourrait être : le dernier à passer sur un nouveau type de contenu est celui qui met en place le formatage des données. Dans ce cas, si le front crée un composant pour afficher un nouveau type de contenu, il va exposer toutes les données qu’il s’attend à recevoir. Le backend va donc devoir formater les données qu’il envoie pour utiliser le composant.
D’autres conventions peuvent être mises en place, comme ajouter un fichier .readme à chaque composant pour exposer les données qu’il peut recevoir, les événements qu’il peut renvoyer, et ce sans avoir à ouvrir le code.
Le DAO permet également de formater l’affichage des données. Il faut comprendre par là que c’est lui qui va, par exemple, formater une date selon le pays courant. Laissant au composant le seul rôle d’afficher l’information.
Ainsi, pour être ami avec les fronts, il suffit de comprendre comment ils visualisent une page web et surtout comment ils en désignent chaque partie dans le code HTML et CSS. Il faut également maintenir un code propre en le réduisant le plus possible. Pas de balises inutiles, mais aussi avoir la connaissance nécessaire des surcharges en CSS. Enfin et surtout, pensez à toujours ouvrir le dialogue pour avoir la même vision des composants et de leurs propriétés ou données attendues.
Merci à Lalie Landry pour la relecture !
Pour aller plus loin
Découvrez en 45 minutes comment booster la performance de vos projets avec JavaScript
Contenus similaires
[ Article ]
Comment GraphQL Codegen améliore l’expérience de développement frontend avec un Backend-for-frontend

Baptiste Leulliette
[ Article ]
L’observabilité 360° : du monitoring technique au pilotage de la valeur digitale

Emmanuel Valluche


