Rafraîchir le front de Drupal : une approche Headless du CMS
25 mars 2021
Le Web a bien changé depuis sa création en 1989 par Tim Berners Lee. Le HTML s’est imposé. Les traitements sur son rendu, réalisés du côté du serveur avec des langages comme PHP sont devenus monnaie courante et ont amené l’essor des CMS, solution simple à mettre en œuvre pour déployer des sites de contenus riches en un minimum d’étapes.
Aujourd’hui, le Web se consomme sur de nouveaux terminaux comme les téléphones mobiles ou les systèmes embarqués. Les systèmes actuels doivent évoluer pour s’adapter aux modes d’accès à leurs informations. On n’a pas les mêmes besoins quand on surfe sur un ordinateur fixe ou un frigo connecté. C’est de ce constat qu’a découlé l’apparition de la notion d’architecture web découplée, appelée “headless” en anglais.
Qu’est-ce que ce terme aux consonances antimonarchistes signifie ? Qu’est-ce que cela peut nous permettre de gagner ? Comment cela fonctionne-t-il avec Drupal et comment le mettre en œuvre facilement ? C’est ce que nous verrons dans cet article.
Qu’est ce que le Headless ?
C’est une approche où la partie responsable du modèle et des contrôleurs d’un modèle MVC – l’ensemble des données et leur traitement – est séparée de la vue – l’affichage des données. Dans notre cas, le CMS fera office de back-end, dans lequel les contenus sont créés. Le front-end est géré par une autre technologie. Les cas les plus fréquents sont l’utilisation d’un framework JavaScript tel que Vue.js ou React. Figures 1 et 2
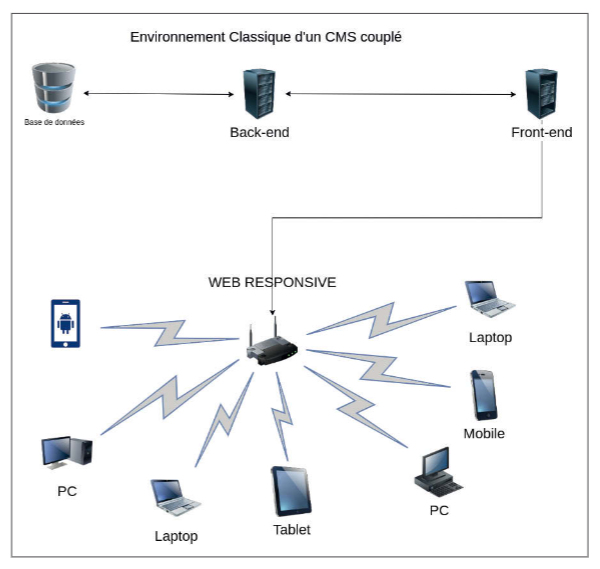
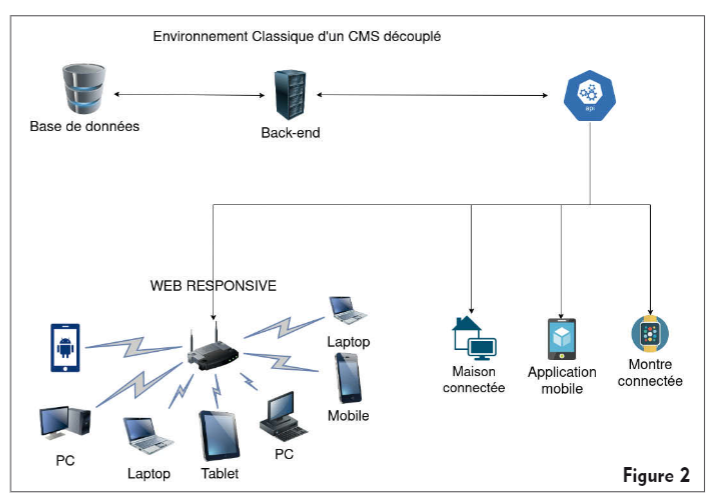
Cette approche présente des avantages certains. Elle permet d’utiliser une technologie prévue à l’origine pour faire du rendu, telle que le React. Ces technologies offrent plus de souplesse et peuvent être plus performantes en fonction des cas d’utilisation. La rupture entre le code et sa présentation facilite la maintenance. Il devient évident de savoir quelle partie gère quoi et donc quelle équipe doit être mobilisée. On peut constater des améliorations des performances, car l’API va limiter le nombre d’appels directs à la base de données, point de friction clef d’une architecture web.
Dans quel cas doit-on envisager cette architecture ?
- Besoin spécifique de la puissance d’une technologie front ;
- Plusieurs plateformes vont afficher les données : mobile, télévision, différentes interfaces web, etc. ;
- Si l’affichage doit être particulièrement adaptable à l’information qu’il affiche ;
- Si le contenu est consommé par de nombreuses cibles, le back-office centralisant les données est un moyen d’éviter la duplication des contenus.
Quelles pourraient être les mauvaises raisons de la choisir ?
- “Headless” est un buzzword. On en entend beaucoup parler. Mais il ne convient pas à tous les projets ;
- Choisir de déléguer le front à d’autres personnes sur une autre technologie parce que personne ne sait le faire en Drupal/Twig ;
- Pour réduire les coûts. Ce n’est pas le cas. Les économies ne viennent qu’avec une mise à l’échelle : plusieurs récepteurs des données fournies par le back, réutilisation des sources… Une configuration spécifique du serveur, pour ouvrir les flux de communication, l’ajout de la gestion des frameworks front… autant d’éléments qui peuvent tirer les coûts de mise en œuvre à la hausse.
L’approche découplée offre des avantages tangibles qu’il ne faut pas négliger :
- La flexibilité : l’affichage s’adapte dorénavant uniquement à la donnée reçue.
- La mise sur le marché de votre solution est plus rapide : la structuration des données n’étant plus nécessaire, il y a moins de temps à consacrer à designer l’interface. De plus, l’agglomération des données peut permettre de générer des pages sans intervention de développeurs. Pour illustrer ce cas, on peut penser à un espace connecté de banque ou d’assurance : beaucoup de blocs qui se retrouvent d’une page à l’autre, en fonction des paramètres.
- Le contenu peut s’adapter à n’importe quel support, puisqu’il n’est pas formaté lorsqu’il est envoyé par le back-office. Ce dernier propose une donnée agnostique qui ne « connaît » pas le support qu’elle sert.
- La sécurité est facilitée à certains niveaux. Notamment, il est plus difficile de programmer une attaque par déni de service (DDoS), car il n’y a plus d’appel direct du front vers la base de données. C’est au niveau de l’API que l’on peut juguler le trafic.
- L’évolutivité des plateformes Web est optimisée : une modification du back-office ne mobilise pas le front-office et réciproquement. Cette séparation peut offrir la possibilité d’avoir deux équipes distinctes, deux prestataires différents, chacun spécialiste de sa partie.
Nous ne voulons pas dresser un portrait trop idyllique sans mettre en garde sur quelques surprises que les administrateurs d’une architecture Headless pourraient rencontrer :
- La plus grande peut être que lors de la contribution du contenu, il n’est plus natif de voir le rendu du contenu nouvellement créé. Cela peut perturber de travailler “à l’aveugle” et peut amener à devoir concevoir un système palliatif en back-office.
- L’autre grande problématique est que le parcours de l’utilisateur n’est plus aussi intuitif que dans une navigation couplée : les cookies et les données de sessions ne remontent plus automatiquement au serveur. Offrir une expérience basée sur le parcours devient alors plus difficile. Il en va de même pour le SEO. Il faut y prendre particulièrement garde pour du contenu référencé. Une anticipation rigoureuse est nécessaire pour les éléments tels que la construction des URL, les balises canonical, les métadonnées, la hiérarchisation du contenu par les balises titres, les sitemaps XML ou encore les CDN.
- Bien que les DDoS soient rendues plus complexes, il faut cependant veiller à correctement protéger les données qui transitent entre le Back et le Front. L’encryptage doit être particulièrement soigné, surtout si les données sont sensibles.
N’oublions pas non plus qu’il faut s’assurer des compétences de ses développeurs lorsque les équipes sont en interne. Une personne qui maîtrise l’intégration du Twig/HTML/CSS ne saura pas forcément faire du Vue.js.
Nous l’aurons compris, le découplage peut transformer votre site web en une véritable expérience. Mais Drupal sait il vraiment le faire ? Pour divulgâcher (« spoiler ») immédiatement la réponse à cette question, nous pouvons vous assurer que la réponse est : oui !
La technologie a pris le virage du Headless dès la sortie de la version 8.0 à la fin de 2015. Depuis, la Communauté n’a eu de cesse d’amener le CMS à la Petite Goutte vers une place majeure dans ce microcosme. Avec une philosophie “API First” et non “d’API Only”, selon les propres mots de son créateur, Drupal permet de gérer aussi bien le couplé que le “sans-tête”. Ainsi, le concepteur du site peut déployer son B.O. tandis que les équipes Front sortent les interfaces utilisateurs indépendamment les unes des autres au fil de l’eau.
Aujourd’hui, le service web de communication RESTful est profondément ancré dans Drupal. Avec un module dédié et un pendant RestUI, pour permettre aux administrateurs de créer des endpoints directement dans le Back-office, sans intervention des développeurs.
Le CMS a su utiliser au mieux ses forces pour permettre une puissance de développement native pour interagir avec les données de manière fluide avant leur envoi vers l’interface.
- Gestion des permissions d’accès avec un contrôle des accès au contenu ;
- Preprocessing et Hooks pour intervenir à plusieurs niveaux sur la donnée durant sa génération et son traitement ;
- La gestion des événements pour augmenter l’expérience utilisateur.
Drupal va même jusqu’à dépasser de nombreux concurrents dont le Headless est la seule raison d’être grâce à sa bonne intégration de la JSON:API, schéma de données permettant de sérialiser et d’exposer des structures complexes. Après de nombreux débats, essais et avancées, la Communauté a fait le choix de concentrer ses efforts sur la JSON:API, qui a été jugée meilleure que RestFul.
Le cahier des charges était strict :
- Le moins de requêtes possibles ;
- API compréhensible et documentée ;
- Solution fiable, sécurisée, facile à mettre en œuvre ;
- Écrire de la data doit être aussi simple que de la lire.
Bien que Rest soit très bien intégré dans Drupal 8, la technologie fait qu’il est souvent nécessaire d’enchaîner les requêtes au serveur pour cibler précisément l’information. Ses requêtes trop verbeuses sont également rebutantes lorsque l’on parle performance ou même impact écologique. La solution GraphQL a également longtemps été dans la balance. Elle aussi répond à de nombreux points. Avec JSON:API, les deux offrent des réponses à la taille limitée, les requêtes et leurs réponses peuvent être mises en cache. Ces mêmes requêtes peuvent être composées côté client. C’est le client qui contrôle également les données. Ce qui allège d’autant plus la charge du serveur.
Cependant, c’est JSON:API qui a gagné “la bataille” grâce à ses arguments indiscutables :
- Pas besoin d’une architecture et de bibliothèques client ;
- Très simple à mettre en place dans Drupal, puis à utiliser ;
- Les fonctionnalités de lecture et d’écriture natives ;
- L’approche de suivre les standards du Web ;
- Son modèle de sécurité.
Les trois technologies sont exploitables, mais le futur s’inscrit dans la JSON:API.
Fort de son architecture et de ses avancées technologiques, il est à noter que la Communauté ne se repose pas sur ses lauriers, en allant chercher une nouvelle solution pour découpler, plus que le contenu, la structure des menus du CMS.
Nous voilà plus éclairés sur l’approche technologique choisie par Drupal, les tenants et les aboutissants, les pour et les contre… Mais comment décider si l’on a besoin d’une plateforme découplée ou non ?
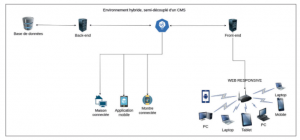
Si, à ce moment-là de l’article, le lecteur ne sait pas comment trancher, alors peut-être que c’est la voie médiane que propose également le CMS qui va pouvoir emporter les suffrages : l’adaptation du progressive headless ou semi-découplage. Un petit schéma plutôt qu’un grand discours saura éclairer ce concept. Figure 3
- Parfait si on a un seul élément très interactif ;
- Ou des sources de données à enrichir ;
- Laisser au BO la gestion du HTML. On envoie des markup déjà prêts (du HTML déjà formaté) ;
- Permet de préserver les interfaces contextuelles et le workflow ;
- On n’envoie que ce que l’on veut. C’est Drupal qui gère ;
- On évite l’architecture plus complexe du découplé ;
- Dernier point et non des moindres, on conserve les puissantes capacités de caches de la technologie.
La joie, autant que les concepts abstraits, nous envahit devant cette pléthore d’approches convaincantes. Mais, cédons à la curiosité de la mise en œuvre d’un Drupal découplé.
Comment faire ?
En tout premier lieu, il est fortement conseillé de travailler efficacement pour anticiper ce qui doit être découplé : qu’est-ce qui sera dans l’API, qu’est-ce qui sera traité par Drupal et surtout pourquoi ? Une fois votre projet parfaitement spécifié, il ne reste plus qu’à créer un nouveau projet Drupal, avec Composer.
composer create-project drupal/recommended-project drupal
Il convient ensuite d’ajouter le module suivant : Jsonapi_extras
Le module de la Json:API, désormais inclus dans le Core de Drupal, n’a pas besoin d’une configuration particulière. Vous pouvez choisir cependant si vous souhaitez que votre API n’accepte que les demandes de lecture ou si vous ouvrez aux CRUD (create, read, update, delete). Pour augmenter un peu le niveau de sécurité de votre API, allez dans la configuration de Json_api:extras (/admin/config/services/jsonapi/extras). Cochez la case pour “Include count in collection queries” et définissez un préfixe de chemin personnalisé. L’exemple trivial est “/api/json/”.
Il ne vous reste plus qu’à consulter, avec Postman par exemple, l’URL de votre API, en mode GET, pour obtenir le fichier JSON comprenant la liste des entités objets de vos requêtes : http://localhost/api/json/node/article
Avec le JSON obtenu, votre Front pourra récupérer chaque nœud, chaque champ et les afficher de la manière qui s’adapte à vos besoins et vos envies.
La procédure que nous venons de décrire est bien évidemment très succincte. Nous vous conseillons de mettre en place un système d’authentification tel que OAuth 2.0 couplé au système de permissions de Drupal. Pour vos premiers tests, vous pouvez essayer le module “simple_oauth”.
La variété de modules de Drupal permet d’avoir déjà un grand nombre de besoins couverts. Vous n’aurez aucun mal à trouver des tutoriels sur la mise en place avancée d’un Drupal semi-découplé ou découplé. Vous avez désormais la majorité des concepts qui permettront d’orienter vos recherches.
Pour aller plus loin
Cet article est tiré du magazine Programmez!
Voir l'article source
Expert technique Drupal
Commentaires
