Serverless pour générer des pages web : bonne ou mauvaise idée ?
25 septembre 2019
Au milieu des concepts d’agilité, de DevOps, de Cloud, de conteneurisation, on entend de plus en plus parler de Serverless. Comme de nombreux buzzwords, il peut se cacher plusieurs définitions pour un seul terme. Voici aujourd’hui une définition de ce que peut être Serverless, et un exemple d’application, avec le projet Neurodiem.
Serverless
On peut parler d’approche Serverless, ou de service Serverless. Serverless signifie littéralement “sans serveur”, mais en réalité, un service dit “serverless” est un service hébergé sur un ou plusieurs serveurs dont on ne se soucie pas, et que l’on peut utiliser à la demande. Un projet utilisant une “approche serverless” est un projet se basant en grande partie sur des services serverless.
Les principaux avantages d’un service serverless sont :
- Le “pay-as-you-go”, on ne paie que ce que l’on consomme. Tous les services Serverless n’utilisent pas cette tarification, mais une grande partie oui.
- La scalabilité, le service alloue autant de ressources que nécessaire.
- Une haute disponibilité, le service (en théorie) ne s’éteint jamais.
- Une réduction du temps de développement
Ces services sont mis à disposition par ce qu’on appelle des “providers”. Ces providers peuvent proposer un ou plusieurs services. Il existe donc des milliers de provider différents, mais nous avons principalement utilisé AWS sur le projet Neurodiem, car c’est ce que nous connaissions le mieux.
Il existe des milliers de services fournis par un grand nombre de providers différents. Ces services sont de tous types : gestion de contenu, gestion de cache, génération de text-to-speech, fonction cloud, hébergement d’images, etc…).
Quel que soit le besoin, un service doit surement pouvoir y répondre, ou un service customisable pourra le combler ! C’est une des forces de l’approche Serverless : tout (ou presque) est faisable.
Un site Web classique
Prenons le cas d’un site Web “classique”. Ce site est hébergé sur un ou plusieurs serveurs, ce qui implique un prix fixe tous les mois. Sur ce(s) serveur(s) sont installés un serveur HTTP, des systèmes de bases de données, de caches, tout ce qui peut être nécessaire au fonctionnement d’un site Web. Dans ce cas, le service HTTP est constamment allumé et facturé, et attend qu’une requête arrive sur le serveur. Quand une requête arrive, le service calcule le résultat en exécutant du code et le renvoie. Ensuite, le service se remet en attente.
Dans ce contexte, il peut y avoir beaucoup de temps pendant lequel le serveur ne fait rien, et il peut y avoir des pics de requêtes en fonction des heures de la journée et/ou de l’usage du site. Il faut donc que le serveur puisse répondre à ces montées en charge, mais ces ressources peuvent être inutiles une partie du temps. Alors, pourquoi ne pas déporter ce calcul dans des fonctions Serverless, afin d’utiliser et de payer des ressources uniquement lorsque c’est nécessaire, et avec une puissance adaptée au contexte ? C’est ce que nous avons fait sur Neurodiem.
Pour cela, nous avons utilisé des Functions As A Service (une fonction exécutée dans le cloud, à la demande), à l’aide du provider AWS. Ce service s’appelle AWS Lambda.
AWS Lambda
Une Lambda est une fonction qui s’exécute en réponse à un événement, et renvoie le résultat. L’événement déclencheur peut être de plusieurs types : modification d’un fichier dans S3, ajout d’une ligne dans DynamoDB, ou un événement HTTP provenant d’Api Gateway.
Lorsque la Lambda reçoit son événement déclencheur, elle va s’allumer, exécuter le code qui lui est associé, retourner le résultat, et s’éteindre. Ainsi, si une requête HTTP est envoyée une seule fois en 24h, le service va tourner durant les quelques secondes d’exécution du code, et s’éteindre : on ne gaspille plus de ressources !

Les Lambdas sont souvent utilisées pour faire des routes d’APIs, et renvoient une réponse HTTP au format JSON. Mais la réponse HTTP est manuelle, il est donc possible de retourner du HTML ! Il suffit pour cela que la fonction de code qui est exécutée retourne du HTML dans le corps de la réponse HTTP, et non du JSON.
On parle d’une fonction de code, car c’est le point d’entrée de la Lambda, mais on peut donner du code complexe, composé de plusieurs fichiers à une Lambda.
Gérer le code d’une Lambda peut être simple, mais plus le site comporte des pages, plus la gestion de ces Lambdas peut devenir compliquée. C’est pourquoi nous avons utilisé le framework Serverless Framework, qui nous a grandement aidé dans la construction du site Neurodiem.
Serverless Framework
Serverless Framework est, comme son nom l’indique, un framework, qui permet d’orchestrer facilement des Functions As A Service. Il n’est pas dépendant d’un provider, et fonctionne tout autant avec Google, Microsoft, AWS, ou autre. Dans notre cas, il nous a permis d’organiser des AWS Lambdas.
Serverless Framework permet de créer des “stacks”, qui sont des collections de Lambdas partageant les mêmes données de code et de déploiement. Une stack est composée de la définition des Lambdas, au format YAML, du code source commun à toutes les Lambdas, et est déployée d’un seul coup (bien qu’une Lambda puisse être déployée unitairement).
Définition des Lambdas et de leurs routes associées :
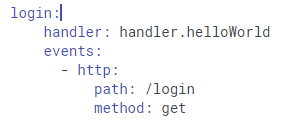
Définition de la fonction associée :
![]()
Lorsque l’on définit plusieurs Lambdas dans une même stack, elles partageront toutes le même code, et seront liées lors du déploiement. Cela peut être très pratique, car certaines classes métiers ou d’accès à des services tiers sont en commun, mais les Lambdas embarquant du code inutile pour elle.
Nous nous sommes basés sur des Lambdas pour la génération de nos pages, mais nous avons également utilisé d’autres services : Contentful pour le CMS, Cognito pour nos utilisateurs, DynamoDB et ElasticSearch pour nos données. Le fait de partager notre code sur toutes nos Lambdas nous a permis de garder commun le code permettant d’accéder et de manipuler ces services.
Un autre avantage de garder toutes nos Lambdas sur la même stack est le versionning et le déploiement. Malgré le nombre de fichiers, nous avons gardé un seul repository git, nous évitant les confusions de synchronisation de versions lors des déploiements. Les déploiements en étaient également facilités, car en une ligne de commandes fournies par Serverless Framework (serverless deploy) nous déployions toutes nos Lambdas d’un seul coup.
Au delà de l’organisation de notre code de “processing”, rien ne diffère d’un site classique en Node, PHP, Symfony, etc.. Il est possible d’utiliser des services tiers, le code HTML renvoyé est interprété de façon classique, rien ne changera au niveau des Js et CSS en front !
Au final, après plus d’un an à travailler avec l’approche Serverless, nous avons pu nous rendre compte de bienfaits de cette approche :
- La rapidité d’installation et d’utilisation des services serverless
- La rapidité de livraison de features utilisant des services serverless
- La facilité de déploiement (une seule ligne)
- La scalabilité automatique en fonction de la charge
- La mise en commun du code qui permet de réutiliser beaucoup de choses
- Le faible coût d’une telle infrastructure
Malgré tous ces avantages, il existe tout de même quelques freins à cette approche, de par son originalité et sa nouveauté. Il y a un temps de prise en main de certains outils qui est non négligeable, et certains services ont des limitations (une stack Serverless sur AWS ne peut pas contenir plus de 200 Lambdas par exemple).
Le fait de partager du code permet de se simplifier la vie, mais nous éloigne d’une approche microservices qui peut être très simple à mettre en place grâce à… des Lambdas !
Comme beaucoup de projets, le choix technologique va dépendre des besoins, du budget, de l’équipe qui travaille dessus, mais l’approche Serverless permet d’être rapidement testée, tout en répondant à un grand nombre de besoins, de par ses vastes services proposés !

Lead Développeur Web
Commentaires
