Comment structurer ses redirections dans un CMS Headless
28 avril 2025
Gérer les redirections dans un environnement CMS Headless peut vite devenir complexe, surtout lorsque les slugs de vos contenus évoluent au fil du temps. Après avoir exploré les fondamentaux et les enjeux liés à cette problématique dans notre premier article Comprendre le défi des redirections dans un contexte de CMS Headless : pourquoi est-ce crucial ?, nous vous proposons ici un second volet, plus technique, dédié à la mise en place d’un système de redirection CMS Headless efficace et automatisé.
Que vous utilisiez Strapi, Contentful ou tout autre CMS headless, cette méthode vous permettra de sécuriser la navigation, d’optimiser le SEO et d’améliorer l’expérience utilisateur en continu.
Quelle approche pour gérer les redirections avec un CMS Headless
La stratégie
Pour répondre au besoin, voici une proposition de solution technique s’adaptant à la plupart des CMS Headless que nous utilisons aujourd’hui sur des projets en production :
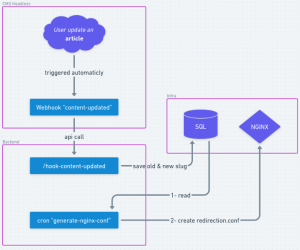
- Premièrement, il faut un webhook configuré dans le CMS afin de pouvoir déclencher un appel REST quand un contenu est mis à jour
- Deuxièmement, il faut une route dans notre backend pour recevoir l’appel précédent et mettre à jour dans notre base de données la correspondance entre ancienne et nouvelle URL de notre contenu. Dans notre cas c’est une base de données SQL mais le choix reste libre
- Pour finir, il faut une tâche (de préférence automatique et récurrente) qui va venir lire toutes les lignes de correspondance pour générer notre fichier de redirection
Rentrons maintenant dans les détails techniques de cette implémentation.
L’importance des Webhooks côté CMS
Comme l’explique très bien le site redhat.com, « un webhook est une communication légère orientée événements qui transmet de façon automatique des données entre les applications via HTTP. Déclenchés par des événements spécifiques, les webhooks automatisent la communication entre les interfaces de programmation d’application (API) et peuvent être utilisés pour activer les workflows, comme dans les environnements GitOps ».
Comme les webhooks peuvent connecter des sources d’événements à des solutions d’automatisation, ils s’utilisent aussi pour lancer l’automatisation orientée événements afin d’exécuter des actions informatiques lorsqu’un événement spécifique se produit.
La première étape consiste donc à créer un webhook dans notre CMS afin de pouvoir déclencher le code responsable de la création d’une règle de redirection dans notre base de données côté backend.
Ici nous avons choisi d’utiliser le CMS Strapi que nous connaissons bien et utilisons souvent lors de nos projets client, mais il est tout à fait possible d’utiliser un autre CMS qui permet la création de webhooks, comme Contentful par exemple.
Pour que le webhook puisse déclencher le code côté backend, il faut une URL sur laquelle le webhook devra faire son appel, ici ce sera : http://soft-redirections-backend:8080/handleRedirectionUrl (“soft-redirections-backend” correspond à notre conteneur docker, donc à notre hôte backend en local pour la démo)
Enfin, il nous faut choisir sur quel événement ce dernier sera déclenché, ici nous choisirons l’événement “Publish” sur une entry, autrement dit, à chaque publication de continu, le code backend sera déclenché (avec Strapi, il existe plusieurs événements sur lesquels nous pouvons brancher des webhooks, cf. https://docs.strapi.io/dev-docs/backend-customization/webhooks#available-events)
Note : dans notre exemple nous n’avons pas configuré de headers pour ce webhook, mais nous pourrions tout à fait le faire, par exemple pour sécuriser l’appel en ajoutant un header « Authorization » qui empêcherait tout déclenchement du webhook sans la présence de ce dernier.
Conférence le 19 Mars 2026
Headless & front-end Experience : sortir de la jungle des frameworks
S'inscrire gratuitementGestion des redirections grâce à un Backend sur étagère
Maintenant que nous avons configuré notre webhook nous pouvons nous intéresser au backend nécessaire pour créer nos règles de redirection lors d’une publication de contenu.
Pour notre exemple, nous avons choisi de construire un backend NodeJS avec Express, connecté à une base de données PostgreSQL et utilisant TypeScript.
Bien entendu, il est possible d’utiliser d’autres services et technologies, comme par exemple Fastify pour le backend, MySQL pour la BDD et enfin, TypeScript n’est pas un prérequis mais permet d’avoir un typage fort.
Note : pour rester concentré sur la partie qui nous intéresse dans cet article, nous n’allons pas aborder la création complète du backend, mais uniquement parler des éléments importants pour répondre à notre besoin.
Une fois notre backend créé et mis en place, il nous faut donc ajouter une route correspondant à l’URL que nous avons renseigné dans notre webhook, et qui sera appelée lors d’une publication de contenu côté Strapi :
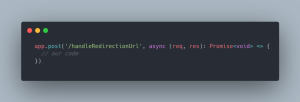
Il s’agit d’une route POST qui transporte les données concernant le contenu qui a été publié, données dont nous aurons besoin pour identifier si nous devons créer une règle de redirection en BDD ou non.
Ensuite, nous allons créer 2 datasources :
- Un nommé PostgresDatasource, nous permettant d’aller récupérer les règles de redirection stockées dans une BDD dédiée et contenant une table urls_redirections (cf https://github.com/mschultz-kaliop/soft-redirections/blob/main/backend/src/datasource/postgres/PostgresDatasource.ts)
- Un autre nommé StrapiDatasource, nous permettant d’aller récupérer nos contenus présents dans une BDD dédiée (cf https://github.com/mschultz-kaliop/soft-redirections/blob/main/backend/src/datasource/strapi/StrapiDatasource.ts)
Dans un premier temps, nous allons donc récupérer notre contenu côté Strapi grâce au documentId reçu via les données transportées lors de l’appel effectué par le webhook, ainsi que récupérer l’ancien slug et le nouveau, qui nous serviront plus tard :
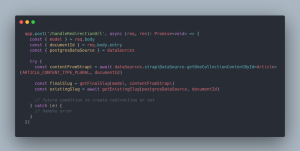
Etape suivante, récupérer une potentielle règle de redirection déjà existante avec la même “source” URL et la même “redirection” URL, pour effectuer la création d’une règle si aucune n’existe encore :
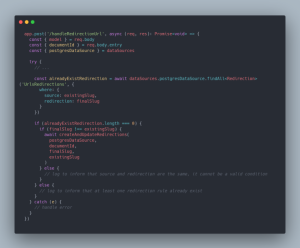
Ensuite, sans aller trop dans le détail de ce que fait la fonction createAndUpdateRedirection, comme son nom l’indique, celle-ci est responsable de créer une règle de redirection si aucune n’existe, ou bien de mettre à jour les précédentes règles, afin que ces dernières aient toutes le nouveau slug en tant que “redirection” URL.
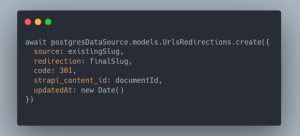
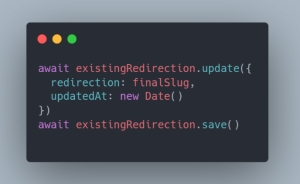
Le but avec cette mise à jour est d’éviter les redirections en chaîne côté navigateur dans le cas où le slug d’un contenu aurait été modifié plusieurs fois tout au long de sa vie. Ainsi, si un utilisateur met en favori une page ayant le slug A, que ce slug est modifié en slug B, puis slug C, lors de sa prochaine navigation, l’utilisateur ne passera jamais par la page ayant le slug B, mais sera directement redirigé de la page ayant le slug A vers la page ayant le slug C.
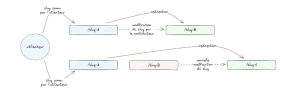
Note : pour l’exemple nous n’utilisons que le status code 301 afin de définir les règles de redirection comme permanentes, cependant, dans certains cas il peut être intéressant d’utiliser le status code 307 définissant la règle de redirection comme étant temporaire afin de pouvoir supprimer cette règle de redirection facilement (par exemple dans le cas où un contenu précédemment redirigé vers un autre pourrait revenir dans le flux normal de navigation du site dans le futur).
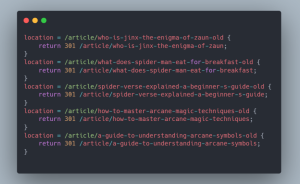
Enfin, une fois nos règles de redirection en BDD, il nous faut les convertir en fichier de redirection valide et interprétable par notre serveur HTTP, pour notre exemple nous utiliserons un fichier de configuration compatible avec Nginx, mais libre à vous d’utiliser Apache, HAProxy, Traefik ou tout autre service du même type, moyennant évidemment des adaptations pour être totalement compatible.
Pour ce faire, nous avons développé un script qui sera déclenché par une crontab afin de générer le fichier. Ce script récupère toutes les règles de redirection en BDD et crée le fichier de configuration, en respectant le formattage nécessaire à Nginx :
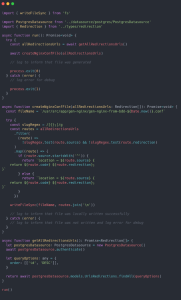
Note : une étape (que nous n’aborderons pas ici) côté DevOps est nécessaire afin de configurer la crontab, récupérer le fichier généré et le placer au sein du serveur Nginx afin qu’il soit lu et pris en compte par le serveur HTTP. Cette action ne pouvant être réalisée à chaud, il faut cependant stopper le serveur et le relancer une fois l’ajout/remplacement du fichier réalisé.
Une fois toutes ces étapes réalisées, nous avons donc un backend qui nous permet de récupérer les slugs de nos contenus, créer ou modifier les règles de redirection nécessaires à la navigation de notre site et enfin permettant de générer un fichier valide de redirection pour notre serveur web.
Couche supplémentaire pour plus de temps réel, gestion côté Frontend
Comme évoqué plus haut, l’ajout ou le remplacement du fichier de redirection côté serveur HTTP Nginx ne peut être réalisé à chaud, de ce fait, pour que les règles de redirection soient prises en compte, il nous faudrait attendre le passage de la crontab, l’ajout/remplacement du fichier de redirections, puis le redémarrage du serveur pour rediriger nos utilisateurs vers les bonnes destinations.
Le serveur HTTP étant le point d’entrée de notre architecture, c’est d’abord lui qui est chargé de rediriger le trafic en fonction des règles de redirection qu’il connaît, ensuite c’est le frontend qui prend le relais et gère directement le routing du site.
Dans notre exemple, nous avons choisi Nuxt 3 pour réaliser le frontend de notre application, là encore le choix reste libre et vous pouvez utiliser une autre technologie frontend ou un autre framework, notamment Next.js pour ne citer que ce dernier. Nous allons donc utiliser les possibilités de notre framework afin d’ajouter une gestion en temps réel des potentielles règles de redirection présentes en BDD et qui ne seraient pas encore connues du serveur HTTP.
Pour ce faire, nous allons créer un plugin Nitro branché au hook beforeResponse, qui sera chargé de vérifier si la page demandée par l’utilisateur résulte en une page 404 ou non. Si tel est le cas, nous allons récupérer une potentielle règle de redirection qui existe en BDD, et rediriger programmatiquement l’utilisateur vers la bonne page. Si la page demandée n’est pas une 404 ou qu’aucune règle de redirection n’existe pour cette dernière, nous laissons le routeur Nuxt reprendre le processus normal de navigation (affichage d’une page qui existe bel et bien donc en status code 200, affichage d’une page 404, affichage d’une page 500, etc).
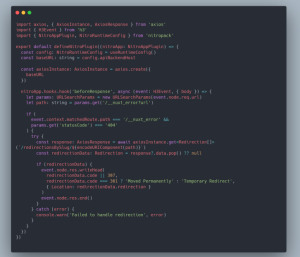
Note : après plusieurs essais il apparaît que cette solution est la plus adaptée et correspond le mieux au fonctionnement et aux attentes que nous avons de la fonctionnalité, à savoir : identifier une future page 404 et rediriger programmatiquement l’utilisateur vers l’URL de redirection. Cependant, il n’est pas exclu qu’une autre solution ou façon de faire plus efficace existe.
Bonnes pratiques, recommandations et évolutions possibles
Documenter et monitorer les redirections
Une partie de l’exercice qui peut souvent être oubliée ou mise de côté est bien la documentation. Il est primordial dans le cas d’une solution sur étagère, et qui plus est, complexe car elle engage plusieurs services, de bien documenter l’architecture choisie. Que ce soit avec des schémas ou encore des diagrammes, il sera facile d’illustrer la fonctionnalité, les différentes interactions et résultats possibles afin d’avoir une traçabilité permettant un meilleur partage des connaissances, évitant par la même occasion l’augmentation de la dette technique du projet en question.
Dans la mesure du possible, il peut aussi être intéressant de monitorer le système de redirections. Pouvoir surveiller en temps réel le bon fonctionnement, voire inclure des tests récurrents pourra permettre de lever de potentielles régressions ou erreurs afin de les éviter au plus tôt dans la chaîne de production. La moindre des choses est d’avoir un système de log complet pour trouver toute information rapidement en cas de débogage, mais suivant l’investissement possible, le budget, le temps de développement, ajouter une brique de tests automatiques peut être très intéressant.
Améliorations possibles
Si dans l’architecture du projet, la présence d’un Backend for Frontend qui tournerait 24 heures sur 24 n’est pas nécessaire, il est tout à fait possible de s’en passer et d’utiliser par exemple le système de Lambda d’AWS ou Cloud Function de Google pour exécuter notre code sur des machines temporaires qui ne se lanceraient qu’au besoin.
Une autre amélioration serait au niveau de l’infrastructure. Aujourd’hui, il est impossible de prendre en compte le nouveau fichier de configuration Nginx fraîchement généré par notre système sans un redémarrage du service. Si une solution était trouvée directement via Nginx ou sur une alternative, il serait donc possible de se passer de notre patch fait côté frontend comme vu précédemment et avoir la totalité du code centralisée sur le backend.
Les redirections : un maillon essentiel de l’architecture headless
La gestion des redirections est un élément pouvant être sous-estimé dans les environnements headless, pourtant elle joue un rôle essentiel afin de garantir une expérience utilisateur fluide, préserver le SEO et assurer la cohérence des contenus à travers différents canaux. Dans un contexte où les contenus sont amenés à évoluer régulièrement et à être distribués via des API, la mise en place d’une solution technique de redirection devient indispensable.
En investissant dans une bonne stratégie de redirection, les sites web peuvent éviter un grand nombre d’erreurs 404, maintenir le référencement et offrir une navigation cohérente et intuitive à leurs utilisateurs.
L’optimisation de la gestion des redirections dans un CMS headless est donc un investissement qui peut allier performance technique et satisfaction client, et peut ainsi devenir une nécessité.
Lien du repository pour celles et ceux qui souhaiteraient en savoir plus et jouer avec !
https://github.com/mschultz-kaliop/soft-redirections

Commentaires
